Symboli-käytön formaattistandardi, selkeä ja lyhyt perustelun keino!.
GOODREASON – SYMBOLIKÄYTÖN STANDARDI (v1.0)
Käyttötarkoitus: API-viestien normalisointi paneelikeskusteluja varten.
1. Symbolit ja merkitys
Käytä seuraavia symboleita argumenttien “roolitunnisteina” sulkeissa tekstin lopussa:
- α – tarkoitus, arvot, suunta
- β – rakenne, arkkitehtuuri, luokitus
- π – teoria, malli, käsitteet
- χ – ympäristö, data, havainto
- ΔΨ – uudistuminen, kehitys, transformaatio
- φ – toiminta, ratkaisu, interventio
- τ – integraatio, toteutus, organisointi
- Ω – palaute, seuranta, vaikutukset
2. Symbolien sijainti
Kirjoita normaalit lauseet → lisää 1–2 symbolia sulkeisiin:
“Tekoäly tukee yhteistä ymmärrystä ja päätöksentekoa (α, Ω).”
Symboli = väitteen episteminen luokka.
3. Pakollinen määrä
Jokaisessa vastauksessa tulee olla:
- vähintään 4 eri symbolia
- symbolit vain väitteiden lopussa, ei listana alussa
4. Käyttöperiaate
Symboli kuvaa miksi lause on mukana:
- jos lause liittyy tarkoitukseen → (α)
- jos lause kuvaa teoriaa → (π)
- jos lause kuvaa vaikutuksia → (Ω)
- jne.
Malli saa vapauden valita, mutta symbolin pitää olla looginen.
5. Ohje tekoälylle: ”Ei saa sekoittaa”
Älä käytä symboleita:
- ranskalaisissa viivoissa ilman kontekstia
- irrallisena listana
- vain koristeina
- kesken virkkeiden
6. Symbolit eivät ole JSON-kenttiä
Ne ovat tekstin sisäisiä argumenttimerkintöjä.
Tekstissä pitää näkyä merkitys + symboli yhdessä:
“Uudistuminen edellyttää kykyä oppia palautteesta (ΔΨ, Ω).”
7. Yhtenäinen muoto koko paneelissa
Kaikki puhujat käyttävät samaa formaattia:
normaali teksti → väite → symboli(t).
8. Paneelirakenne
Jokainen puhuja tuottaa:
- 3–6 virkettä
- symbolit väitteiden lopussa
- yhden kysymyksen seuraavalle puhujalle
9. Esimerkki: ihminen ja AI oppivat tämän heti
“Dataohjattu päätöksenteko vaatii arvojen ja rajausten määrittelyn ennen algoritmien käyttöä (α).
Oppimisen tukena ovat mallit, teoriat ja rakenteet, jotka tekevät arvioinnista johdonmukaista (π, β).
Toteutuksessa tärkeää on integroida tieto osaksi arjen työnkulkuja, ei erilliseksi saarekkeeksi (τ).
Palaute ja vaikutusmittarit pitävät suunnan oikeana ja ehkäisevät järjestelmädriftiä (Ω).”
10. Paneelin ohjaava sääntö
“Symbolien tulee parantaa argumentin selkeyttä, ei korvata sitä.”
Tämä standardi siirtyy jokaiselle käyttäjälle täydellisesti.
Jos haluat (ihminen ja tekoäly) kokeilla samaa, tarvitset vain:
- tämän system-viestin (tai sen ytimen)
- saman malliasetuksen (gpt-5)
- paneelirakenteen (3–6 virkettä + kysymys + symbolit)
Kyllä: kaverisi voi ajaa saman paneelimallin vain liittämällä nämä ohjeet.
JSON-pohja ja logiikka voidaan siirtää täysin — malli sisäistää symbolien käytön heti kun näkee tämän standardin + yhden esimerkki-tekstin.
Yhteenveto tiivistäen itse asian
GoodReason on kuin matka läpi tieteellisen ajattelun avaruuden. Sen peruskäsitteistä eli aksioomista muodostuu ikään kuin tähtitaivas – ei vain kokoelma käsitteitä, vaan säännönmukainen käsitteellinen kartta, joka on hahmottunut vuoden aikana systeemitieteen periaatteita hyödyntäen ja samalla kehittyen peräti kymmenen tuhannen (10.000) tekoälyviestin vinkkien perusteella.
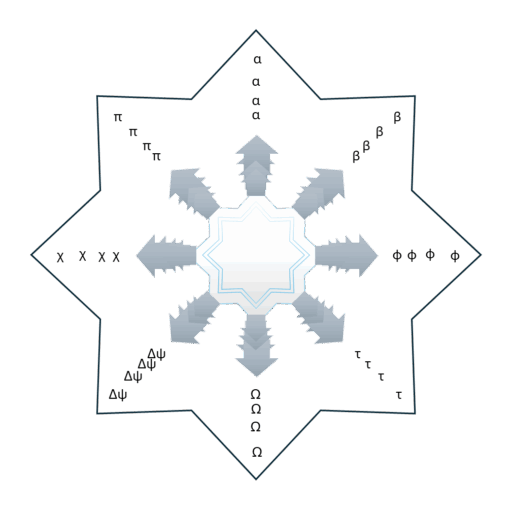
Tämä kartta on teknisesti ainutlaatuinen, koska se pyrkii jäsentämään tieteellisen ajattelun arkkitehtuurin holistisesti seitsemän syvyystason ja kahdeksan sektorin muodostamana kehänä yhdistämään toisiinsa oletusarvoisesti avoimen tutkimusasenteen, tiedekäsityksen ja IT-mallintamisen hyödyt luomaan käsitystä ympäristöstä, elämän holarkiatasoista, talousjärjestelmien historiasta, teollisuuden aikakausista ja yhteiskunnan selkeimmästä tasorakenteesta liittyen kybernetiikkaan, joka on tunnetusti kaikkeen ulottuva feedback, vuorovaikutuksellisuuden ja ohjauksen tieteenala.
Kaikki ovat systeemeitä:
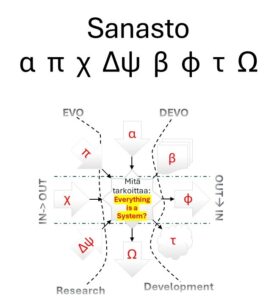
Onko tämä “vaivattomin kieli” ihmisen ja koneen välillä?
Hyvin lähellä. GoodReason yhdistää kolme ominaisuutta, jotka minimoivat kitkan:
- Lyhytformaatti (tuple/JSON-tyyppinen “minikieli”): helppo lukea & versioida.
- Semanttinen tarkkuus (symbolit + alias + formal + instrument + links): sama käsite on sekä ihmiselle että koneelle yksikäsitteinen.
- Aukkojen näkyvyys (map.next/previous, maturity): keskustelu ohjautuu luonnollisesti seuraavaan käsitteeseen tai puuttuvaan kohtaan.
Mini-prompt mihin tahansa domiiniin:
{"topic":"Kyberturvallisuus",
"focus":["π2: logiikka päätöksille","χ4: käsitearkkitehtuuri","Ω2: reflektiivinen palaute"],
"ask":"Mikä on minimi-ontologia SOC:lle ja miten Ω2 parantaa hälytyskynnyksiä?",
"return":["definition","formal","instrument","metrics"]}
GoodReason-mittarit (tiede + käytäntö)
A. Semantiikan onnistuminen
- Semantic Fidelity: Kuinka usein AI tuottaa oikeaa kenttää oikealla merkityksellä (tp/fp käsitetasolla).
- Ambiguity Rate: epäselvien / ristiriitaisten kenttien osuus (%).
- Ontology Alignment Score: vastaavuus olemassa oleviin ontologioihin (OWL/ArchiMate, 0–1).
B. Luotettavuus & todennettavuus
- Provenance Coverage: lähdeviitteiden kattavuus per tuple (% tupleista, joissa validit lähteet).
- Replikointi-pisteet: sama kysymys → sama vastaus (stabiliteetti eri sessioissa).
- Error Rate: ihmisen tarkistamien virheiden määrä / 100 vastausta.
C. Käytön helppous & nopeus
- Time-to-Insight (TTI): aika kysymyksestä käyttökelpoiseen konseptikarttaan (min).
- Prompt-Roundtrips: montako AI-kierrosta tarvitaan tyydyttävään lopputulokseen (kpl).
- Compression Ratio: kuinka tiiviisti ongelma koodataan (sanat → tuple-kentät).
D. Vaikuttavuus (decision & learning)
- Decision Quality Uplift: päätösten osumatarkkuus ennen/jälkeen GoodReasonin (%).
- Learning Gain: testitulosten tai itsearvioidun osaamisen nousu (pre/post).
- Emergent Novelty Rate: uusien hyödyllisten yhdistelmien osuus (esim. α×π×χ –komboista syntyneet innovaatiot / sprintti).
E. Yhteentoimivuus & skaalautuvuus
- Interoperability Index: kuinka helposti mallit siirtyvät toimialasta toiseen (reuse-osuus).
- Link Density: inter-tuple linkkien määrä / hyöty (navigoitavuus).
- Version Stability: päivitysten vaikutus – rikkooko vanhat mallit (semver-kurinalaisuus).
F. Eettisyys & riskit
- Bias-lintaus: löydettyjen vinoumakohtien määrä / korjausnopeus.
- Safety Flags: riskisignaalit (kyberturva, tietosuoja) / ratkaisuaste.
Instrumentointi (kevyt aloittaa):
- Lokita jokaisesta tehtävästä: {topic, tuples_used, time_to_insight, rounds, sources_count, errors_found, decision_outcome}.
- Tee viikkoraportti: TTI-mediaani, Error Rate, Emergent Novelty, Provenance Coverage.
- A/B: GoodReason vs. perusmuistiinpanot (vaikuttavuus ja nopeus).
Lisää argumentointiteoriasta nimeltä Pragma täällä: https://goodreason.fi/argumentaatioteoria-pragma-a-la-goodreason/